
Provisioning Gitlab runners on AWS with an optimised infrastructure design
In this age of agile development over containerised microservices, manual deployment is too cumbersome of a process. Keeping a tab of the versions deployed on all environments for each microservice, provisioning an upgraded deployment at the development of every new feature or bug fix, maintaining the specific configurations and databases in synchronisation with the development process, and whatnot! 😓
Thus emerges a need for continuous integration and continuous deployment over an automated infrastructure.

In BranchKey, we solved this problem using Gitlab CI/CD. This choice was made mainly because we already use Gitlab as our VCS, and thus extending to the native CI/CD integration seemed to be an obvious first approach.
GitLab CI/CD can be integrated into the system infrastructure as separate entities called runners. Gitlab provides its own free runners, with a limited resource and time usage. To be able to control the usage parameters, we at BranchKey, decided to deploy our own runners. These can be deployed as Docker containers, or as individual VM instances.
We decided to explore the VM deployment option using AWS infrastructure. The easiest approach would have been to deploy multiple EC2 instances, each of which would serve as a single runner. But this would not be the most cost efficient way. We could schedule them to turn off during the non-working hours, but would still be charged for multiple large instances running unused most of the time.
It is always preferred to optimise infrastructural costs as much as possible 💰
Thus, we came up with an alternative. The idea, as shown in Figure 1, was to deploy a single very small EC2 instance running all the time, and ready to accept GitLab pipeline jobs whenever needed. Since this is a small VM (preferably a t4g.nano), it would not add to a lot of operational cost. But given its small size, it won’t be capable enough to run the jobs. Thus, it would spawn a larger EC2 instance (could be t3a.large) every time there is a job available, run the job over this new instance, and shut it down once done.
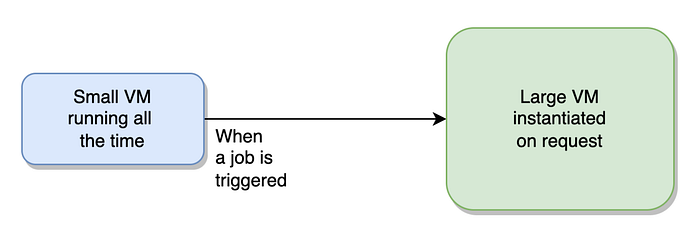
While this seemed like a perfect approach, it gave errors while configuring. GitLab Runner configuration file exposes auto scaling parameters, where IdleCount defines the number of runner machines in idle states. Given the low usage of BranchKey, we wanted this to be zero. This meant spawning an instance when a job is available, and kill it later, keeping no instance idle. However, instance was not being killed, and rather, a new instance was being spawned at every job. This is an open issue in GitLab. This would mean multiple EC2 instances running infinitely, and thus adding to infrastructure cost for no reason. Contrarily, when the IdleCount value was being set to something other than zero, instances were getting created on AWS one after the other without any of them being actually getting allocated to a job. This issue is also open in the community.
Hence, we had to discard this approach entirely.

Exploring further, we decided to give the container runner deployment a try. This would mean running the gitlab-runner process as a docker service on an EC2 instance. We followed the official documentation to install, configure and register the runner, and it worked successfully 🎊🎉 , except that two issues were encountered:
- Access issues for GitLab servers in accessing the runner instance in a private subnet in AWS. This was resolved by provisioning an elastic load balancer to grant access to this private instance.
- A TLS issue in the DIND (Docker in Docker) ecosystem, where the docker containers of the jobs were not able to communicate with the base docker image of the runner. This was resolved by mounting the ca-certs volume into the runner docker instance, as described here.
In attempts to optimise infrastructure resource usage, we could spawn multiple of these runner processes in different docker containers on the same instance. Since it was a large instance, we could provision upto 3 runners on each. This was better than provisioning an instance for each runner separately. Further, we provisioned a very small EC2 instance, as shown in Figure 2, to schedule these large instances. A cronjob to start and stop the large instances in accordance with the working hours of the developers was deployed on this small instance.

This not only gave us control over our gitlab runners, but also allowed us to provision them in a cost effective manner. Additionally, it can be scaled as per need 💯
The whole process of arriving at this solution was not easy, but definitely worth it. Although it did seem tempting to use Gitlab’s own runners at first, this exercise did give us an idea of how things work underneath, and a better understanding of CI/CD as a tool. We at BranchKey believe in experimenting with things, while also maintaining resource efficiency. Watch this space for more such stories from our implementation cycles! 🎊🎉