
Enhancing our consumer platform to provide federated learning at scale.
From a software engineer’s perspective, BranchKey provides a consumer platform which exposes APIs to perform federated learning and download the aggregated results. We authenticate and authorise every incoming request using our in-house solutions, cache the input files, asynchronously aggregate them, and notify the clients when an aggregation result is ready to be downloaded.
Needless to say, all of this is designed as a microservices architecture
Inception of BranchKey happened with the prototyping of a federated learning algorithm. Python, as a programming language, became the obvious choice because it provides a wide community support for such data science problems. To maintain consistency in technical stack, we extended the use of Python for other microservices as well. For instance, our Authentication Service implements Python Flask, with a PostgreSQL DB backend.
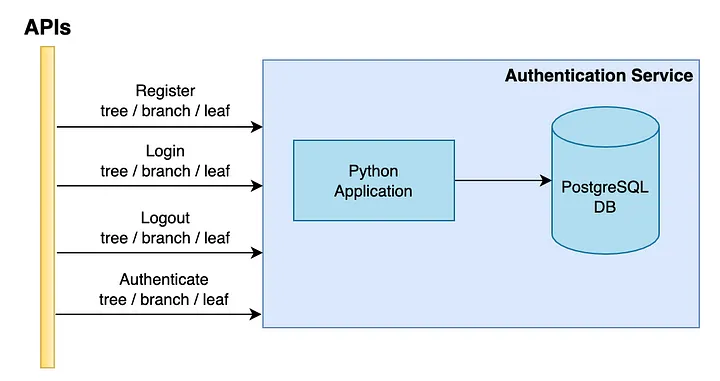
This looked promising. We followed all the Flask framework conventions to develop a production grade service. Subjecting to a load-testing script which fired about 25 requests per second for each of the APIs, we obtained a response time of about 150 ms. This isn’t that bad! Especially when we were using a Kubernetes single pod deployment on a machine with 2 vCPUs and 4 GBs memory. Our service used only 0.7 of the CPU and 325 MBs of memory!
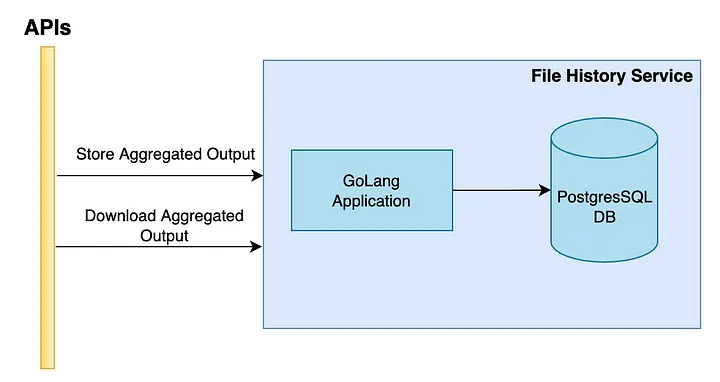
Meanwhile, as an experiment, we started exploring GoLang for software development. There occurred a use case for a similar CRUD application with a PostgreSQL DB backend. We needed a File History Service to store the aggregated result files, and serve them on demand. The index data of each file was stored in the PostgreSQL DB.
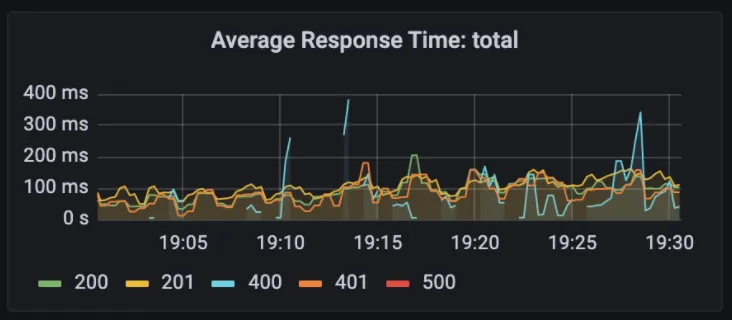
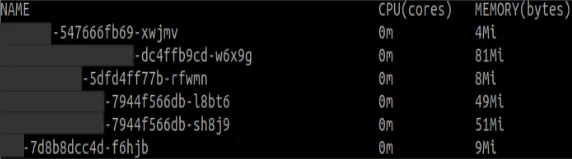
To our surprise, for the same load, this service responded within 30 ms 😱 Further, it used only 0.05 of the CPU and 23.5 MBs of the memory 🤯
We were bound to dig around more into this. Since both these services were essentially performing read and write operations on a PostgreSQL backend, such a massive difference in performance and infrastructure usage would directly affect the scalability. More so for authentication service, because every incoming request is mandatorily authenticated. Digging in, we discovered that within our ecosystem, a Python application takes up about 9 times more memory than a GoLang application in no-data and no-load state.
As a result, except the federated learning algorithm, most of our consumer platform is now being developed in GoLang
But why?!
- GoLang is a compiled language which generates machine code for execution, it outperforms interpreted scripting languages like Python.
- GoLang is built for high concurrency. Unlike multi-threading in Python, GoLang works with goroutines. As stated here, they basically enable software based concurrency rather than hardware based. A single OS thread could facilitate a 1000 goroutines.
- In terms of memory usage, as Dave Chaney states, Python consumes about 6 times more memory than GoLang to store similar variables.
- Additionally, for memory allocations, GoLang not only exploits compile time interpretations like C/C++, but also uses a run time garbage collector like Java. This surpasses the lack of memory management in Python.
These not only lead to lower memory usage and faster processing, but also lower the need for computation power.
While there are many blog posts out there which compare Python and GoLang in terms of ease of writing and maintaining code, seeing the effects of infrastructural performance was exciting. They not only sold us over the goodness of GoLang, but also convinced us to rewrite the existing Python services.
As a result, except the federated learning algorithm, most of our consumer platform is now being developed in GoLang.